
NOTE : Please read Part 1 before proceeding further . Part 1 discusses isolation levels , roll ptr and other basic concepts . This article has advanced content and is hard to understand unless you grasp the concepts from Part 1
Read-view computation
CREATE TABLE `t` ( `id` int(11) DEFAULT NULL, `c` char(30) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t values (10, ‘newark’), (11, ‘san francisco’), (12, ‘washington’);
Let’s assume following 2 transactions that are trying to modify the table listed above. (transaction statements are ordered based on timestamp).
trx-1 (trx-id=m)
BEGIN; SELECT * FROM t; [newark, san francisco, washington] SELECT * FROM t; [newark, san francisco, washington] UPDATE t SET c = “newyork” WHERE id =10; [1 ROW updated] SELECT * FROM t; [newyork, san francisco, washington] commit; zSELECT * FROM t; [newyork, san jose, washington]
trx-2 (trx-id=m+1)
BEGIN; SELECT * FROM t; [newark, san francisco, washington] UPDATE t SET c = “san jose” WHERE id = 11; [1 ROW updated] SELECT * FROM t; [newark, san jose,washington] SELECT * FROM t; [newark, san jose,washington] commit; SELECT * FROM t; [newyork, san jose, washington]
- Trx-1 is trying to modify given row with id = 10.
- Trx-2 is trying to modify given row with id = 11.
- As we can observe from output above, both transactions are able to see their updated row immediately but are not able to see other transaction modified row.
- Even after trx-1 get committed, trx-2 continue to maintains its original snapshot of the table with its local modification.
This raises some important questions?
- How does transaction know which data to read for corresponding row ?
- Is each transaction maintaining copy of the table for its own reference ?
- If (2) is true then and when and how are these copies merged ?
- If copies are not maintained then even though trx-1 is committed how come trx-2 don’t see the changes done by trx-1 [updating newark = newyork].
Answer to this lies in MVCC. InnoDB maintains copies of the rows as they get modified and each transaction know which copy is meant for its purpose. Let’s understand how.
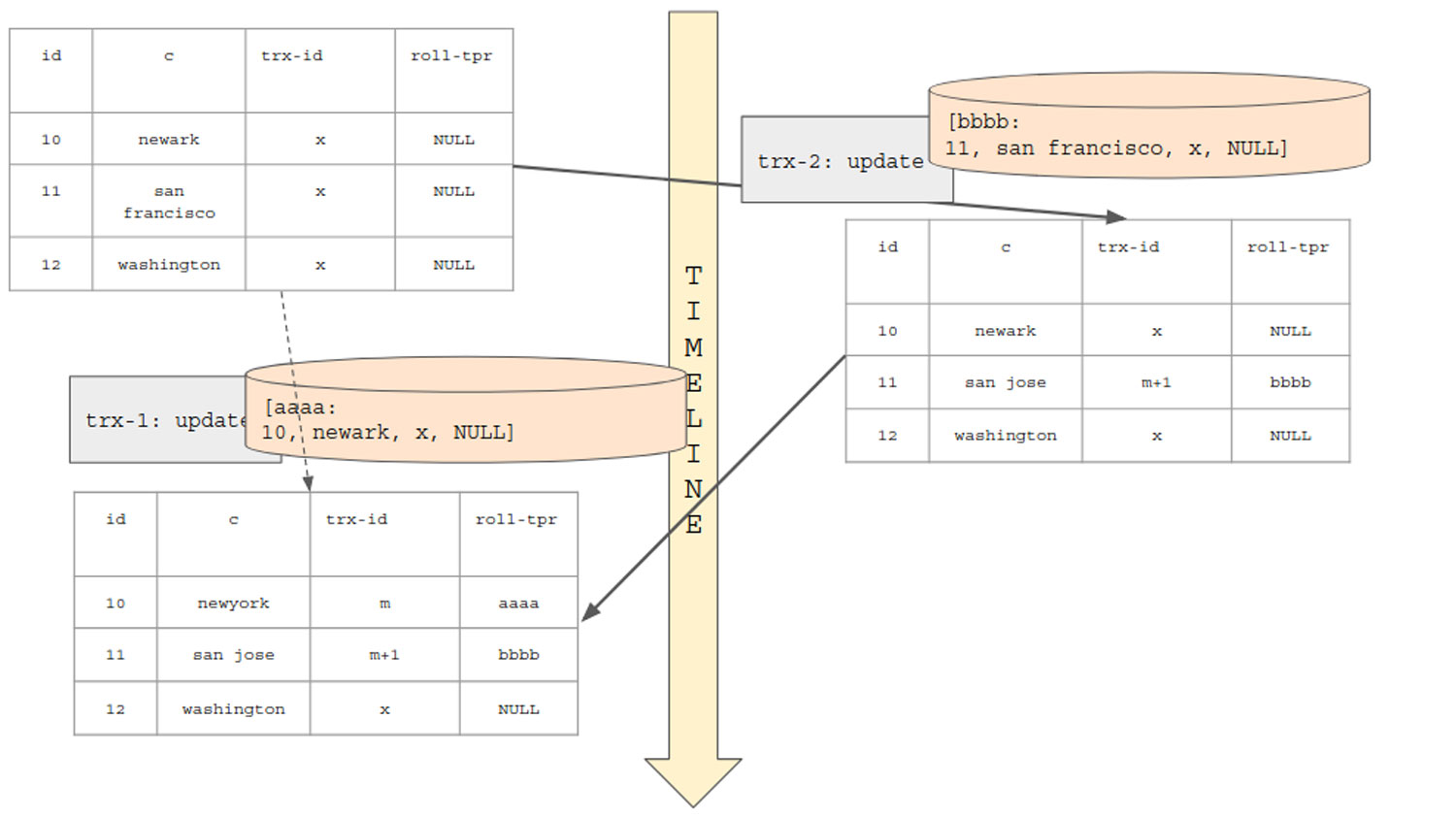
- Diagram above represent how the structure of the table continue to change as the timeline progresses. As we can see table is not copied and changes are made inline but the old version of the said records are cached to the respective undo-logs/rollback-segments.
- Rollback-segment are attached a respective transactions and records the changes done by any given transaction which may include update to the multiple data objects.
Let’s understand how read-view is defined:
When a transaction (with trx-id=m) came into existence there were no other active pending transactions. So it created a view such that it:
- can see all objects that has been updated by transactions with trx-id <= m (this include self object).
- can’t see all objects that will be updated by future booting transactions with trx-id >= (m+1).
- VIEW-RANGE: [0, m].
- InnoDB doesn’t include the self transaction id as part of the range while displaying the range. So the range displayed by InnoDB for this transaction would be [0, m-1]. Self changes are always visible so assumed.
When a transaction (with trx-id=m+1) came into existence there was one active pending transaction with trx-id = m. So it created its view such that
- can see all objects that has been updated by the transactions with trx-id <= (m-1) (can’t see data-object changed by trx-id = m)
- can’t see all objects that will be updated by transactions with trx-id >= (m+2) [ensure it sees data-object changed by it own].
- VIEW-RANGE:[0, m-1] && [m+1,m+1]
- To simply this understanding imagine that when the transaction read-view come into existence it captures snapshot of the table ignoring the uncommitted transactions. So as we can see above, when both transaction came into existence they based their original snapshot on the state that exist with committed transaction (in our case m-1 transaction committed state).
- Transaction of-course sees its own changes but doesn’t see the changes done by other transaction once the read-view is defined (including future booting transaction).
Now let’s understand how transaction re-prepare the original state of the table if the state of table is changing on the fly with other transaction updating the same table.
a. In our use-case when the first select post update was fired by trx-1 it retrieved the data w/o any changes from trx-2. This is made possible by trx-id checks.
b. trx-2 made changes to table and cached the original row in the rollback segment. Updated row has trx-id=m+1. When trx-1 started scanning table (t) it started evaluation filter as follows:
- row-1 (id=10): trx-id:x <= (m) (TRUE) ====> qualified.
- row-2 (id=11): trx-id:(m+1) <= (m) (FALSE) ====> traverse the list of db-roll-ptr to fetch version that has trx-id <= (m).(This search yields a cached copy in rollback segment (referred by bbbb) with trx-id:x <= (m)). Traverse and Found.
- row-3 (id=12): trx-id:x <= (m) (TRUE) ====> qualified.
c. Now when trx-1 made changes and trx-2 was trying to evaluate the table this is how it would proceed.
- row-1 (id=10): trx-id:m <= m-1 [|| trx-id:m+1 == m+1] (FALSE)====> traverse the list of db-roll-ptr to fetch version that has trx-id <= (m-1).(This search yields a cached copy in rollback segment (referred by aaaa) with trx-id:x <= (m-1)). Traverse and Found.
- row-2 (id=11): trx-id:m+1 < (m-1) [|| trx-id:m+1 == m+1] (TRUE) ====> qualified.
- row-3 (id=12): trx-id = x < m ([|| trx-id:m+1 == m+1]) (TRUE) ====> qualified.
d. Same evaluation will apply if there are more than N transactions. Each transaction will cache the original version of row it is trying to update to its respective rollback segment.
On transaction commit
Once transaction commit, its rollback segments may continue to still remain valid as there could be other transaction that still needs this version of rollback segment. This is not applicable to insert undo logs. (insert undo logs? Yes there are 2 types of undo logs: INSERT and UPDATE). Insert undo logs/rollback segments cache newly inserted data by the given transaction. Since the data is newly inserted, other transactions will not carry reference to it. This allows transaction to free INSERT rollback segments. UPDATE rollback segments need to be retained till the last referencing transaction is done with it.
Once transaction is committed, if user fire SELECT from the said session, this new SELECT will be treated as read-only transaction and will read the latest data as it exist in the table given that it can see the said snapshot.
Removal of rollback segment
In above case once trx-1 is committed, can update rollback segment be removed immediately ?
- As explained above, since trx-2 still needs the old version of the updated row, trx-1 created rollback segment can’t be removed.
- But then when does these rollback segments get cleaned up ? This is where purge comes into picture.
- Purge is background operation and it tracks which all update rollback segments can be removed once the all referring transaction are done with it.
With that let’s introduce concept of history length.
Concept of History Length
Say a transaction has opened a read-view and user has not yet committed it. In meantime N different transactions has made changes to the said table (in our case table is really small but imagine if real use-case table where it make sense for N different transactions to make changes to different rows). On completion of these N different transactions their respective update rollback segment can’t be released because the said transaction still need old-version copy of the said table rows.
This is where the history length start. A long running transaction can cause pile up of rollback segments.
History length can be formally define as length/number of unpurged undo/rollback segments.