
Table of Contents
What is included in this blog post ?
This is part 2 of the Aurora postgres series . In part 1 https://klouddb.io/aurora-postgresql-gotchas-part-1/ we covered below topics
- Shared_buffers config is different
- Pg_hba file cannot be updated in Aurora
- Max_connection defaults are different in Aurora
- Pg_stat_statements reset issue
In this part we cover 4 more differences between Aurora Postgres and Community Postgres
Aurora and disk space issues - Temporary files
“Disk space incidents” are common in onprem environments . With the advent of cloud, these incidents are reduced . But are we 100% free from disk space incidents in cloud environments ? The answer is “No”. We can still see some disk space incidents (Depending on config and workload) .
Here is an excerpt from AWS Aurora documentation . There is automatic resize feature in Aurora which is really good to prevent “disk full issues”

You start using Aurora cluster and one fine day you might hit “”ERROR: could not write block XXXXXXXX of temporary file: No space left on device.”
What is this error ? How come we ran into disk space issues with Aurora ?
Aurora postgres uses local storage for temporary files , error logs etc.. This local storage is limited e.g t3.medium gets 7.5 GB and r4.large gets 30GB and so on .. Please read here for detailed info on the limits by instance type
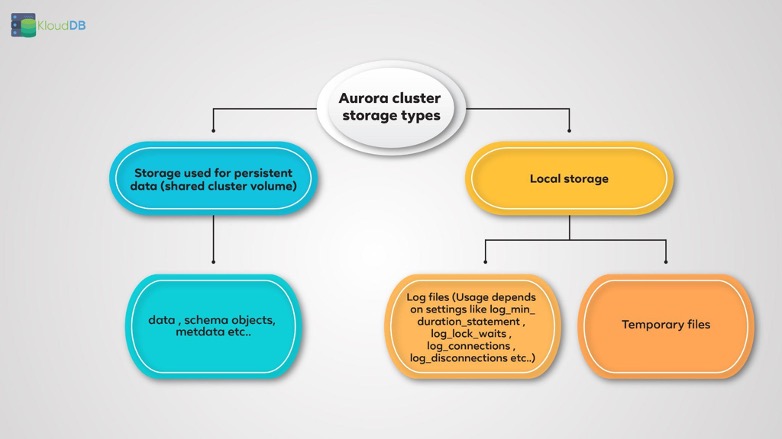
You need to monitor temp file usage , log file usage closely to avoid these issues in production . Only a DBA can proactively address this issue , So RDS/Aurora needs a DBA and dont think that you can manage your cloud db services without a DBA . Please read our blog on temporary files in Postgres here https://klouddb.io/temporary-files-in-postgresql-steps-to-identify-and-fix-temp-file-issues/ . Also read our other blogs on “RDS needs DBA” here https://klouddb.io/managing-rds-postgresql-logs-rds-needs-dba-2/
Aurora default settings are not the same as community postgres ?
By default track_io_timing is disabled in community postgres whereas it is enabled in Aurora Postgres(Version 14). This is just one example and there are many other parameter differences between community postgres and Aurora postgres

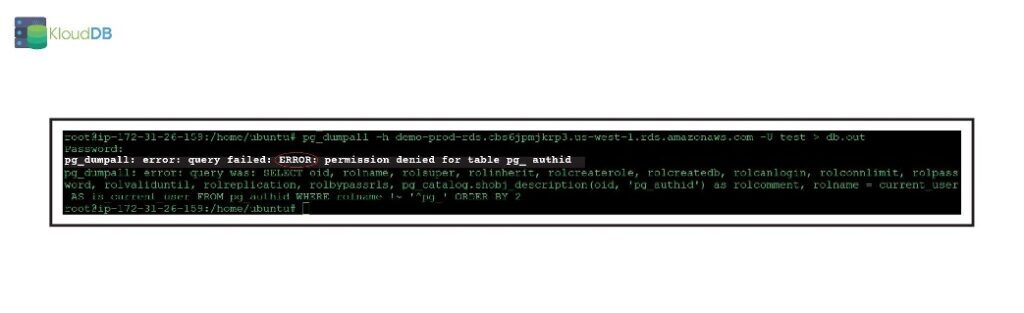
Pg_dumpall and permissions issues
In part 1 of the series we presented a permission issue related to reset of pg_stat_statements. You might also run into permission issue when you try to use pg_dumpall(screenshot below). Please use –no-role-passwords flag to fix this issue
Invoking Lambda via trigger in Aurora
You can invoke lambda functions from your Aurora instance using functions like “aws_lambda.invoke”. You need to install aws_lambda extension to use this feature . For detailed information please visit https://aws.amazon.com/blogs/database/enable-near-real-time-notifications-from-amazon-aurora-postgresql-by-using-database-triggers-aws-lambda-and-amazon-sns/
Below extension is used to invoke Lambda

Conclusion
Managing Aurora Postgres is similar to community version but there are subtle differences as illustrated in these two blog posts . Below are the differences covered in these two posts

We will be posting more such scenarios in part 3. Please also check our other performance articles – Pgbouncer multiple instances , Postgres and temporary files , Pgpool and performance tuning, How we improved Lambda performance by 130x etc..
Looking for Postgres support ? Please reach us at support@klouddb.io